
Cross-Domain Few-Shot Learning for Mobile OCR
Anyline Engineering Team
Engineers at Anyline
This blog post highlights the ongoing collaboration between Anyline and Machine Learning researchers from the LIT AI Lab at Johannes Kepler University Linz. We demonstrate the application of the Few-Shot learning method CHEF [1], which was recently published by our collaborators from Linz. The experimental study based on typical Anyline use-cases shows the great potential of the CHEF approach.
Introduction
Today, businesses are confronted with highly dynamic and ever-changing market requirements. In such environments, quick and highly accurate data capture solutions are essential to help businesses bridge the gap between their analog and the digital data. Now, as the world deals with the COVID-19 pandemic, the need for reliable and robust and contactless data capture solutions has become more important than ever..
It’s common knowledge that the performance of the machine learning (ML) algorithms was always related to the amount of available data. But roughly ten years ago, new deep learning approaches started to emerge from the Computer Vision community, bursting through nearly every known dataset’s benchmark. These successes were primarily related to the sophistication of ML-models and learning algorithms, the growing computing power of machines, and the explosion in high-quality annotated data available for training state-of-the-art ML-models.
In some application areas, collecting and annotating the data is relatively fast and straightforward. However, in many other areas, producing a large-high-quality training dataset is still a real challenge. The curation of such datasets can be extremely time-consuming and sometimes requires a human’s expert knowledge. This in turn drastically increases the costs needed to produce training data, as well as the time consumed for creating reliable data capture solutions.
It became evident to us that we would need to devise novel machine learning techniques that are less data intensive while keeping high accuracy at the same time. The field of research focusing on reducing the amount of training data needed is often referred to as Few Shot Learning (FSL) or N-Shot Learning, which describes the ability to learn from a limited number of examples (denoted by N).
According to the survey [2], there are three main groups of FSL approaches. They mainly focus on using the prior knowledge to
- augment training data;
- constrain model/hypothesis space, and;
- alter search strategy in hypothesis space.
The first group aims to extend the training set by duplicating and altering the data, transforming samples from a weakly labeled or unlabeled dataset, or transforming examples from similar datasets.
The second group tries to exploit prior knowledge of the model hypothesis space, thus reducing the complexity of a learning problem. This group includes a multi-task learning – simultaneous training of multiple models with shared weights on various tasks. Another example is embedding learning, which aims to transform each sample into a lower-dimensional space such that one can use a simple similarity measure to distinguish between two samples.
The third group’s goal is to leverage prior knowledge to obtain the model’s parameters, for example, by refining the existing parameters or learning the optimizer.
Relevance
The adoption of few-shot learning methods for our business use cases is driven by the following factors:
- Scarce data: Normally, customers provide only a limited amount of sample images. These images usually exhibit a very limited variability and could be subjected to selection bias. FSL methods aim to mitigate the influence of the latter.
- Reducing data collection and computational costs: few-shot learning methods aim to reduce the amount of training data. This, in turn, considerably decreases the costs related to data collection and labeling. Furthermore, having a smaller training dataset can reduce related computational costs.
- Learning rare cases: for example, in OCR, an ML model trained with few-shot learning techniques can classify even rare characters correctly after being exposed to small amounts of prior information.
FSL methods therefore allow us to build highly accurate ML models by exploiting the prior knowledge of the domain similarity supported by as few data as possible. That, in turn, leads to more agile product development and much faster product delivery. In other words, FSL helps us to serve our customers with solutions in a much shorter timeframe.
This blog intends to validate one of the novel FSL methods known as CHEF: Cross-domain Hebbian Ensemble Few-shot learning [1], which was recently published by our collaborators from the LIT AI Lab at Johannes Kepler University Linz. This approach is specifically designed to overcome the problems arising from domain shifts that occur when the distribution of input and/or target image domains changes considerably.
The remaining part of the blog comprises a brief outline of the main features of the CHEF, an experimental part, and a discussion, where we apply FSL to mobile OCR use-cases and outline the most interesting findings.
Method: Hebbian Ensemble Few-Shot Learning
Deep neural networks consist of a hierarchical structure of layers. These layers maintain different representations of the input data, which differ mainly in their level of abstraction. Let us consider the example of convolutional neural networks and how they process images. Layers close to the input layer capture low-level structures like edges or small textures. Layers close to the output layer represent high-level structures like the presence of more complex shapes or entire objects.
As we introduce a larger domain shift, the high-level concepts will eventually stop working. For example, if a network is trained to classify animals, it will have high-level features to recognize things like legs, eyes, fur textures, etc. If this network is then used to classify buildings, it will not encounter these kinds of objects anymore. This, however, does not mean that the network does not bear any useful information about the new task. But to access it, we have to dig deeper into the network structure.
CHEF (cross-domain hebbian ensemble few-shot learning; [1]) combines features from layers of different levels of abstraction. This means that even when the high-level representations crumble, features of lower layers can take over and still allow for a decent prediction result. We call this concept representation fusion. It allows a flexible choice of the right level of abstraction for the few-shot task at hand, depending on the size of its domain shift. We implement representation fusion using an ensemble of Hebbian learners operating on distinct representation levels in parallel. The results of these learners are then combined into a single prediction.
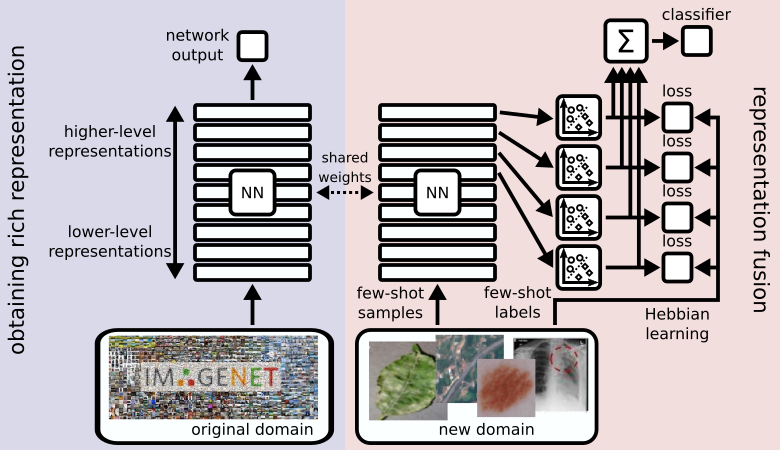
Application
Many limitations arise when it comes to deploying artificial neural networks on mobile devices for real-time scanning. These limitations include the size of the neural network, it’s inference time, and the complexity of the underlying operations. In order to validate the CHEF approach and determine its applicability to mobile OCR, we created a classifier resembling the well-known AlexNet [3] convolutional architecture. For the experiments in this blogpost, we have chosen an architecture that consists of two convolutional blocks (each having two consecutive convolutional layers) followed by a max-pooling layer and three successive fully-connected layers (see figure below).
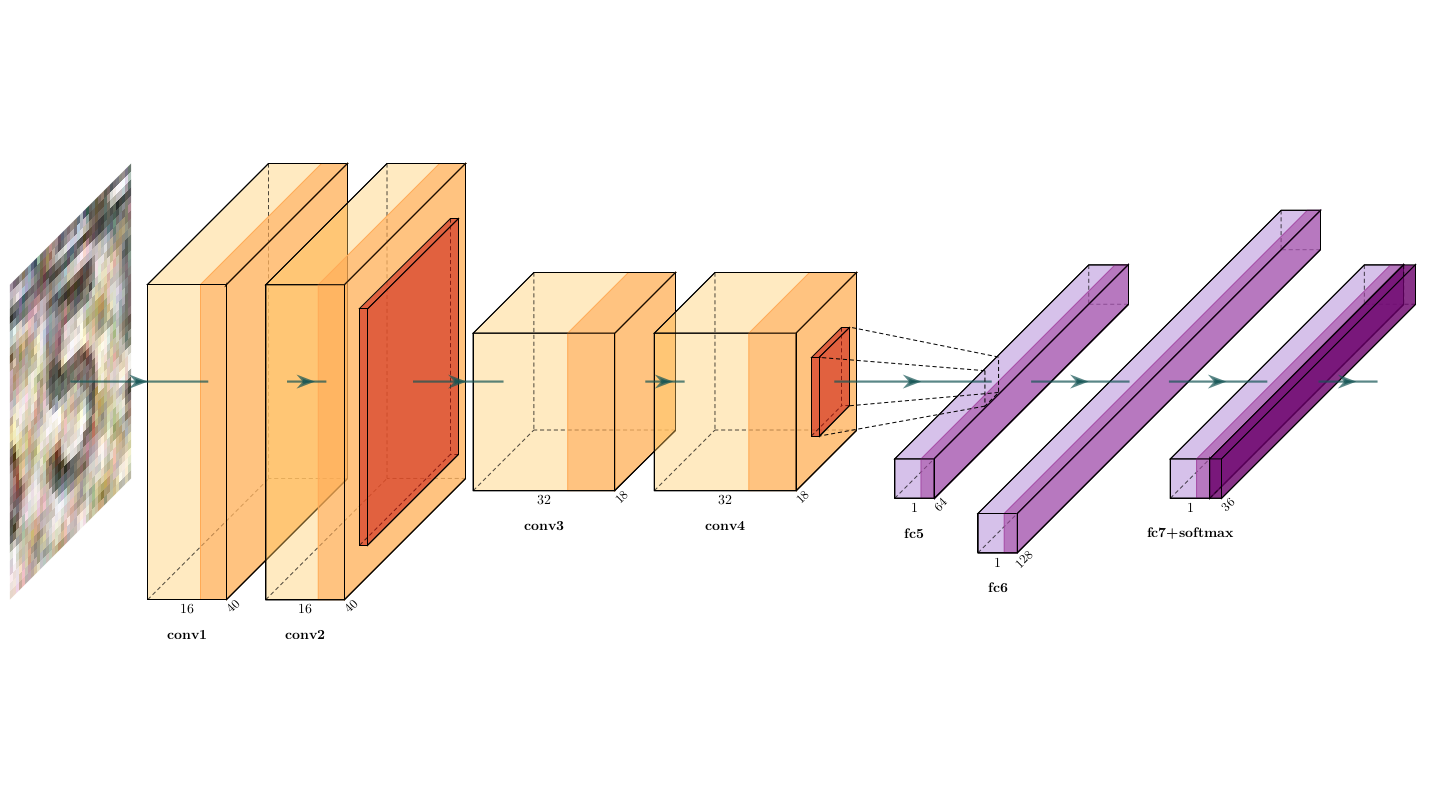
Let’s call our experimental network a generic scanner network (GSN). We train it to classify digits (0,1,…,9) and latin capital letters (A,B,C,…,Z). The corresponding training dataset for GSN includes images from the several domains:
- serial numbers and digits on analog meters;
- characters of Vehicle Identification Numbers (VIN);
- serial numbers on shipping containers;
- synthetic data of approximately 70 sans serif fonts;
The figure below shows typical image examples from the source domain.

The target domain comprises the images of the digits (0,1,…,9) carved on a metal plate. The main challenge of this use case is the absence of any distinct font color. Therefore, the visual appearance of the digits in the images, to a great extent, depends on the positioning and the type of light source, be it natural ambient light or any artificial light source (e.g., indoor lamp, night street light, flashlight of the mobile device).
The following figure shows common examples of the metal plate’s digits.

Experiments
In our FSL experiments, we apply representation fusion to the following GSN layers: conv4, fc5, and fc6. Each of these layers is associated with a Hebbian learner that extracts useful information from the respective feature vector and contributes the final model predictions. In case of conv4 feature map, we investigate two strategies:
- a standard Hebbian learner (denoted by “conv4”) that operates on a flattened convolutional feature map;
- a convolutional layer with 3×3 kernel followed by a global average pooling layer (later denoted by “conv4 (c)”).
To explore the impact of the sample size on the final model’s accuracy, we perform several experiments on scarce datasets of 5, 10, and 15 shots/examples per each character class.
Note that digit classes (0,1,…,9) occur in both source and target domains. Therefore, we utilize a whitelisted GSN model with no fine-tuning as a baseline. The whitelisting transformation is performed by truncating the weight matrix of the last dense layer and keeping only the row vectors associated with the whitelisted characters. A similar procedure is also applied to a bias vector.
In this study, we also compare the CHEF approach with the model fine-tuning for GSN. In the latter, we completely replace the classification head of the neural network and retrain only the last layer while freezing the remaining weights. Then the whole network is fine-tuned for several epochs with a reduced learning rate.
As mentioned in the introduction, image augmentation is also considered to be one of the techniques which mitigates the limitation of having only a small amount of data. In this study, we also investigate the impact of online augmentation methods on the model’s accuracy. The augmentation pipeline includes such transformations as random cropping, random brightness-contrast adjustments, gaussian blurring, and additive Gaussian noise.
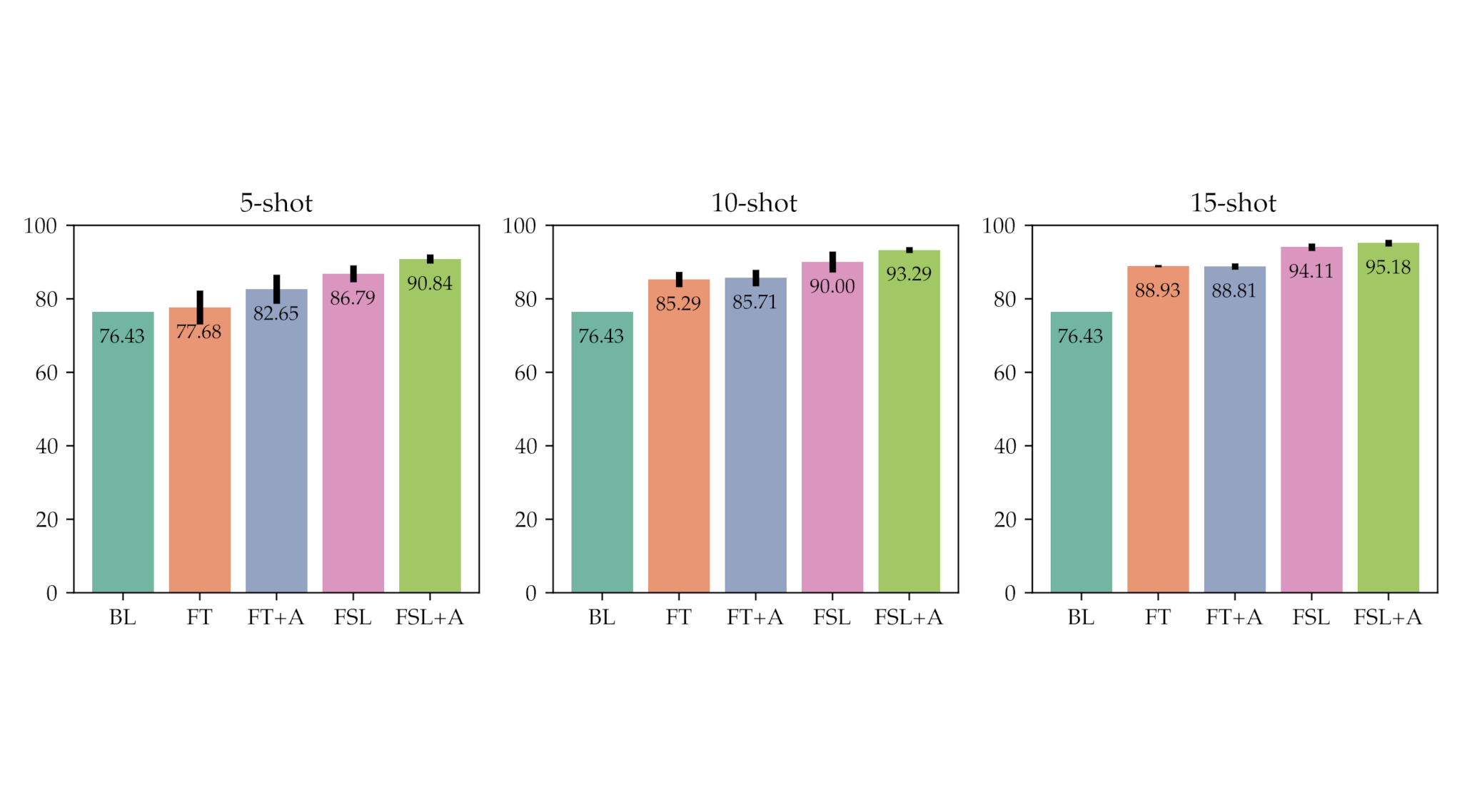
The figure below illustrates the comparative study of the following approaches:
- baseline, whitelisted GSN model (“BL”);
- fine-tuned GSN model (“FT”);
- fine-tuned GSN model with image augmentation (“FT+A”);
- a few-shot learning approach – CHEF (“FSL”);
- CHEF with image augmentation (“FSL+A”);
To further analyze the power and impact of the representation fusion, we conducted an ablation study by measuring the accuracy of individual Hebbian learners as well as the accuracy of the entire ensemble model.
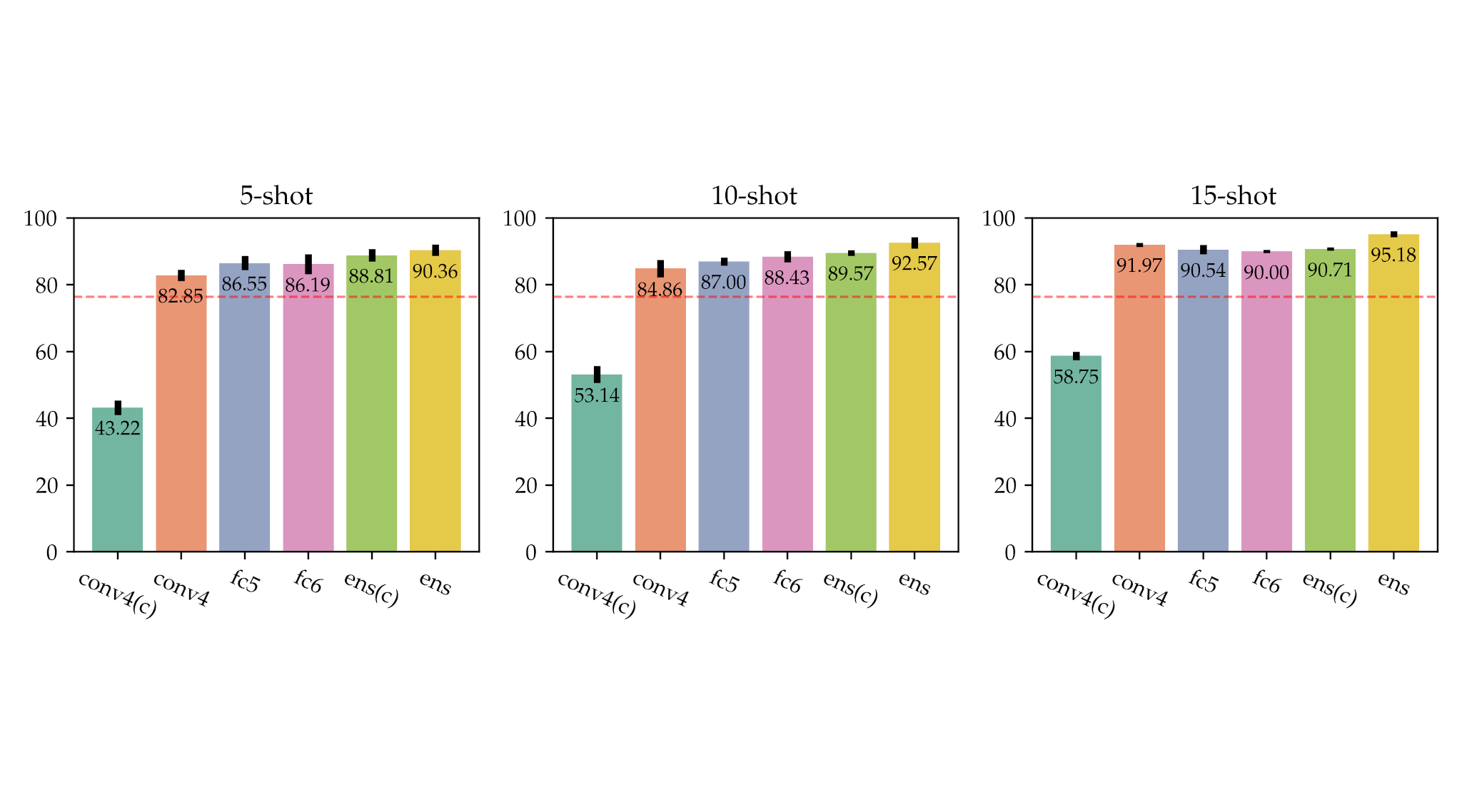
The figure above shows the results of the ablation study for 5-, 10-, and 15-shot learning tasks. The bar plot indicates performances of individual Hebbian learners and two ensemble models: “ens” combines Hebbian learners “fc6”, “fc5”, and “conv4”; and “ens(c)” fuses “fc6”, “fc5”, and “conv4(c)”. The red dashed in the barplot line indicates the accuracy of the baseline model (the whitelisted GSN): 76.43%.
Discussion
The experiments conducted show that few-shot learning techniques allow us to train extremely accurate models based on scarce data. The main outcomes of this study can be summarized as follows:
- Representation fusion with CHEF allows us to improve the accuracy of the baseline model by +14-18%. The CHEF approach also outperforms the fine-tuning approach by approximately +7%. The accuracy of the representation fusion increases as we add more samples per class.
- Combining CHEF with online augmentation allows us to gain a performance boost of +4% for a 5-shot learning task. However, the augmentation becomes less efficient as we increase the number of samples per class;
- By testing the different combinations of Hebbian learners, we discovered that the best accuracy could be achieved by activating all three Hebbian learners.
- The training time of the CHEF has significantly decreased since each Hebbian learner is independent of the others; therefore, the whole ensemble can be trained in parallel.
- Convolutional layers followed by global average pooling did not provide sufficient benefit in comparison to Hebbian learners.
- Real-world datasets rarely contain an equal amount of samples per class. Therefore, it becomes important to address the problem of long-tailed data distribution in the context of few-shot learning.
Conclusions
In this blog post, we have analyzed the current status of few-shot learning (FSL) research. As shown by the growing number of publications, few-shot learning remains an active and promising research topic. Existing techniques have already achieved very high accuracy based on scarce data. Applying the methods outlined in this blog allow us to drastically reduce the costs of data collection, annotation and minimize the required computations. Moreover, FSL methods allow us to train ML-model even on rare case examples.
We have validated a novel FSL approach known as CHEF, which was recently published by our collaborators from the LIT AI Lab at Johannes Kepler University Linz [2]. It builds on the concept of representation fusion that unifies information from different levels of abstraction and allows us to fully utilize the knowledge stored in a pre-trained model.
CHEF achieves new state-of-the-art results on many cross-domain few-shot learning benchmarks. We have tested the performance of CHEF in the case of mobile OCR. The performed experiment showed a significant boost in accuracy in comparison to the baseline and alternative approaches demonstrating great potential for mobile OCR applications.
Authors
Dmytro Kotsur (a), Stefan Fiel (a), Thomas Adler (b), Cezary Zaboklicki (a), Martin Cerman (a), Hubert Ramsauer (b), Sebastian Lehner (b), Christian Pichler (a)
(a) Anyline GmbH, (b) Institute for Machine Learning & LIT AI Lab, Johannes Kepler University Linz. The LIT AI Lab is supported by Land OÖ.
References:
[1] T. Adler, J. Brandstetter, M. Widrich, A. Mayr, D. Kreil, M. Kopp, G. Klambauer, and S. Hochreiter, “Cross-Domain Few-Shot Learning by Representation Fusion”, arXiv preprint arXiv:2010.06498, 2021.
[2] Y. Wang, Q. Yao, J. Kwok, and L. M. Ni, “Generalizing from a Few Examples: A Survey on Few-shot Learning”, ACM Computing Surveys, 53 (3), 1-34, arXiv:1904.05046, 2020.
[3] A. Krizhevsky, I. Sutskever, and G. E. Hinton. “Imagenet classification with deep convolutional neural networks”, Advances in neural information processing systems, 25, 1097-1105, 2012.

